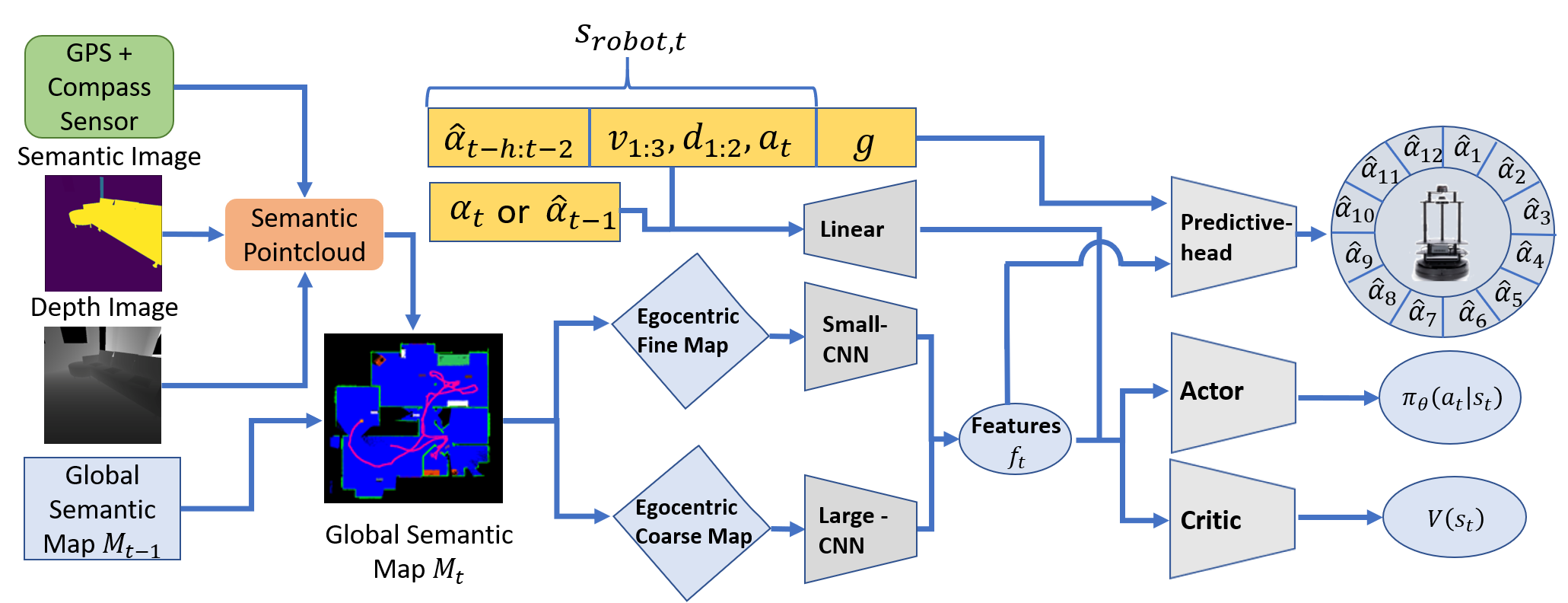
Recent advances in vision-based navigation and exploration have shown impressive capabilities in photorealistic indoor environments. However, these methods still struggle with long-horizon tasks and require large amounts of data to generalize to unseen environments. In this work, we present a novel reinforcement learning approach for multi-object search that combines short-term and long-term reasoning in a single model while avoiding the complexities arising from hierarchical structures. In contrast to existing multi-object search methods that act in granular discrete action spaces, our approach achieves exceptional performance in continuous action spaces. We perform extensive experiments and show that it generalizes to unseen apartment environments with limited data. Furthermore, we demonstrate zero-shot transfer of the learned policies to an office environment in real world experiments.
Learning Long-Horizon Robot Exploration
Strategies for Multi-Object Search in Continuous Action Spaces
Fabian Schmalstieg, Daniel Honerkamp, Tim Welschehold, Abhinav Valada